Whisper — найточніше open-source розпізнавання мовлення
Транскрипція аудіо · Переклад мовлення · 99+ мов · Безкоштовно і без передачі даних
Навчений на 680 000 годин аудіо · Точність наближається до людської
- Що таке Whisper і чим він відрізняється
- 3 способи використання: без коду, API, локально
- Без коду: no-code застосунки на базі Whisper
- Через OpenAI API: два рядки коду
- Локальна установка Whisper
- Розміри моделей: від Tiny до Large
- Основні команди і параметри
- Python інтеграція для розробників
- Формати виводу: TXT, SRT, VTT, JSON
- GPT-4o Transcribe: наступник Whisper
- Для чого використовувати Whisper
- Whisper vs конкуренти
- Поради та лайфхаки
- Часті запитання
🎯 Що таке Whisper і чим він відрізняється
Whisper — це Automatic Speech Recognition (ASR) модель від OpenAI побудована на архітектурі encoder-decoder Transformer. На відміну від комерційних сервісів транскрипції (Google Speech, Amazon Transcribe, Microsoft Azure), Whisper є повністю відкритим вихідним кодом під ліцензією MIT — тобто безкоштовним для будь-якого використання включаючи комерційне.
Ключова особливість Whisper — це навчання на масивному і різноманітному датасеті. 680 000 годин аудіо зібраних з інтернету включали різні акценти, фонові шуми, технічний жаргон і множинні мови. Результат — модель що чудово справляється з реальними умовами запису де спеціалізовані системи часто помиляються.
Станом на 2025 рік Whisper V4 досягає приблизно 3.2% Word Error Rate (WER) на англійській мові — це наближається до людської точності (4–5% WER для досвідчених транскрибістів). Для порівняння, ранні версії ASR систем мали WER 15–25%.
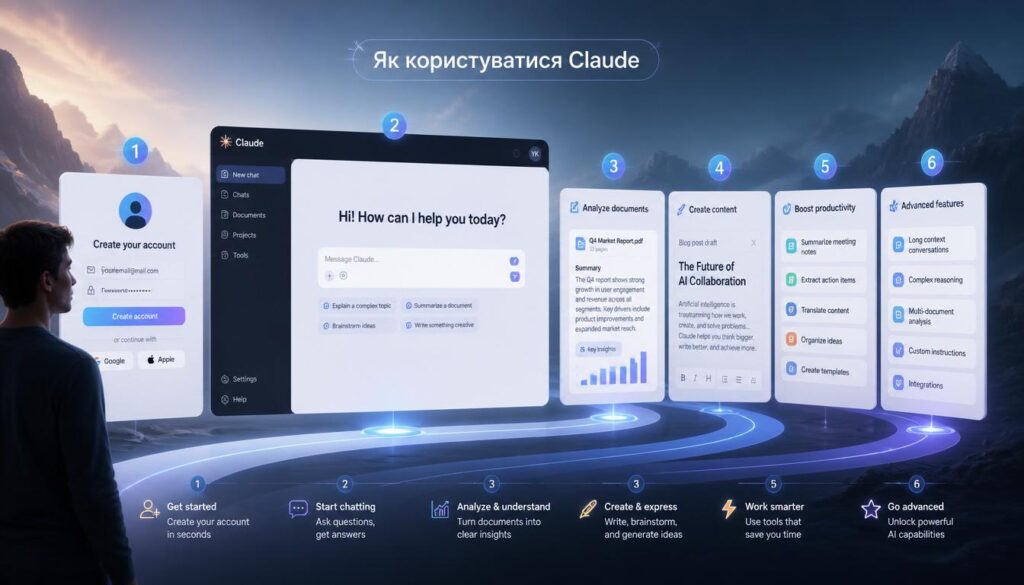
🗺️ 3 способи використання: без коду, API, локально
Whisper підходить для дуже різних користувачів — від нетехнічних людей до розробників. Ось три основні шляхи залежно від вашого рівня і задач:
🖱️ Без коду: no-code застосунки на базі Whisper
Якщо вам не потрібно писати код — скористайтесь готовими застосунками що використовують Whisper під капотом і мають зручний графічний інтерфейс:
🔌 Через OpenAI API: два рядки коду
Якщо ви розробник і хочете інтегрувати транскрипцію у власний застосунок — OpenAI надає хмарний API. Це найпростіший спосіб почати без локальної установки. Вартість: $0.006 за хвилину аудіо для whisper-1.
pip install openai
# Транскрипція аудіо — мінімальний приклад
from openai import OpenAI
client = OpenAI(api_key=“your-api-key”)
with open(“audio.mp3”, “rb”) as audio_file:
transcript = client.audio.transcriptions.create(
model=“whisper-1”,
file=audio_file,
language=“uk”, # uk для української
response_format=“text”
)
print(transcript)
with open(“meeting.mp3”, “rb”) as f:
result = client.audio.transcriptions.create(
model=“whisper-1”,
file=f,
response_format=“srt”, # субтитри одразу
prompt=“AI Explorer, ChatGPT, Anthropic, Cursor AI” # підказка термінів
)
print(result) # готовий SRT файл
💻 Локальна установка Whisper
Локальна установка — найкращий вибір для конфіденційних даних, великих обсягів і регулярного використання без хмарних витрат. Потрібен Python 3.8+ і pip.
Встановіть Python
Якщо Python ще не встановлений — завантажте з python.org (версія 3.8 або новіша). Перевірте: python --version
Встановіть ffmpeg
Whisper потребує ffmpeg для обробки аудіо. macOS: brew install ffmpeg. Windows: завантажте з ffmpeg.org і додайте до PATH. Ubuntu: sudo apt install ffmpeg
Встановіть Whisper через pip
Відкрийте термінал і виконайте: pip install openai-whisper. Встановлення займає кілька хвилин.
Перша транскрипція
Виконайте: whisper audio.mp3 --language uk. Whisper автоматично завантажить потрібну модель (перший раз — займе кілька хвилин залежно від розміру).
Перегляньте результати
У тій самій папці з’являться файли: audio.txt, audio.srt, audio.vtt, audio.tsv, audio.json — всі формати одразу.
whisper audio.mp3 –language uk
# Велика модель для максимальної точності
whisper audio.mp3 –model large-v3 –language uk
# Тільки SRT субтитри, без інших форматів
whisper video.mp4 –output_format srt –language uk
# Переклад будь-якої мови на англійську
whisper ukrainian_speech.mp3 –task translate
# Пакетна обробка кількох файлів
whisper *.mp3 –model medium –language uk –output_dir ./transcripts
pip install faster-whisper. Це оптимізована реалізація яка працює в 2–4 рази швидше оригінального Whisper з тією самою точністю завдяки квантизації CTranslate2.📊 Розміри моделей: від Tiny до Large
Whisper доступний у кількох розмірах — більша модель означає вищу точність але потребує більше пам’яті і часу. Обирайте залежно від потужності комп’ютера і вимог до точності:
| Модель | Розмір | Швидкість (CPU) | Точність | Ідеально для |
|---|---|---|---|---|
| ⚡ Tiny | 39M | ~10x реального часу | Базова | Чернетки, слабкі пристрої |
| 🚀 Base | 74M | ~7x | Добра | Щоденне використання |
| ⚖️ Small | 244M | ~4x | Висока | ✅ Рекомендовано (баланс) |
| 🎯 Medium | 769M | ~2x | Дуже висока | Складне аудіо, акценти |
| 💎 Large-V3 | 1550M | ~0.5x (потрібен GPU) | Максимальна | Профі, GPU є |
⌨️ Основні команди і параметри
uk (українська), en (англ.), de, fr. Без цього — автовизначенняwhisper interview.mp4 \
–model medium \
–language uk \
–task transcribe \
–output_format srt \
–output_dir ./subtitles \
–initial_prompt “Інтерв’ю про AI технології, Anthropic, ChatGPT”
🐍 Python інтеграція для розробників
Для інтеграції Whisper у Python-застосунки можна використовувати бібліотеку напряму без командного рядка:
# Завантаження моделі (кешується після першого завантаження)
model = whisper.load_model(“small”)
# Транскрипція файлу
result = model.transcribe(
“audio.mp3”,
language=“uk”,
task=“transcribe”
)
# Повний текст
print(result[“text”])
# Сегменти з таймкодами
for segment in result[“segments”]:
print(f“{segment[‘start’]:.1f}s → {segment[‘end’]:.1f}s: {segment[‘text’]}”)
from faster_whisper import WhisperModel
model = WhisperModel(“small”, device=“cpu”, compute_type=“int8”)
segments, info = model.transcribe(“audio.mp3”, language=“uk”)
for segment in segments:
print(f“[{segment.start:.2f}s] {segment.text}”)
📄 Формати виводу: TXT, SRT, VTT, JSON
Whisper автоматично генерує результати у кількох форматах одночасно. Кожен підходить для різних задач:
📝 Plain Text
Чистий текст без таймкодів. Ідеально для статей, нотаток, пошуку у тексті
🎬 SubRip
Стандартний формат субтитрів. Підтримується VLC, YouTube, Adobe Premiere, DaVinci Resolve
🌐 WebVTT
Субтитри для вебу. Використовуйте у HTML5 відео тегах і стрімінгових платформах
📊 Таблиця
Таблиця: початок/кінець/текст. Відкривайте в Excel або Google Sheets для аналізу
🔧 JSON
Повні дані: текст, таймкоди, ймовірності, мова. Для програмної обробки і API
📦 Всі формати
–output_format all генерує всі п’ять форматів одночасно. Зручно для першого разу
🆕 GPT-4o Transcribe: наступник Whisper
У березні 2025 року OpenAI випустила нові моделі транскрипції що перевершують Whisper за точністю — gpt-4o-transcribe і gpt-4o-mini-transcribe. Вони доступні тільки через API і не є відкритим кодом.
| Модель | WER (точність) | Ціна | Open-source | Ідеально для |
|---|---|---|---|---|
| 🎤 whisper-1 (API) | ~5.2% WER | $0.006/хв | ❌ API | Існуючі інтеграції |
| ⚡ gpt-4o-mini-transcribe | ~3.6% WER | ~$0.003/хв | ❌ API only | ✅ Нові API проєкти |
| 💎 gpt-4o-transcribe | ~2.8% WER | ~$0.006/хв | ❌ API only | Максимальна точність |
| 💻 whisper large-v3 (локально) | ~3.2% WER | $0 (свій GPU) | ✅ MIT | Приватність і контроль |
🎯 Для чого використовувати Whisper
⚖️ Whisper vs конкуренти
⚡ Поради та лайфхаки
🎙️ Якість аудіо = якість транскрипції
Навіть найбільша модель Whisper не може компенсувати погане аудіо. Перед транскрипцією — очистіть запис від шуму через Audacity (Noise Reduction) або Adobe Podcast Enhance Speech (безкоштовний). Різниця у точності може бути 15–20% на зашумленому аудіо.
📝 Використовуйте –initial_prompt для термінів
Якщо у вашому аудіо є специфічні назви, терміни або жаргон — додайте їх у параметр --initial_prompt. Whisper використовує підказку для контексту і рідше помиляється у незнайомих словах. Наприклад: --initial_prompt "Anthropic, Claude, LLM, трансформер, ембедінги"
⚡ faster-whisper для CPU
Якщо у вас немає GPU — обов’язково спробуйте faster-whisper. Ця реалізація використовує квантизацію int8 і CTranslate2 що дає 2–4x прискорення на CPU при тій самій точності. Особливо помітно на моделях medium і large.
🔄 Автоматизація з ffmpeg
Поєднуйте Whisper з ffmpeg для автоматизованих pipeline. Наприклад: витягти аудіо з відео → транскрибувати → записати SRT → спалити субтитри у відео — все одним bash-скриптом без ручної роботи.
--language uk явно. Автовизначення мови іноді плутає українську з російською на коротких фрагментах. Явна вказівка мови також прискорює обробку і підвищує точність на ~5–10%.❓ Часті запитання
--language uk явно, використовуйте модель medium або large, забезпечте чисте аудіо без сильного шуму. У порівнянні з англійською точність дещо нижча — це нормально для мов з меншим представленням у навчальних даних. Але для більшості практичних задач якість цілком прийнятна.✅ Підсумок
Whisper від OpenAI — найкращий безкоштовний інструмент для розпізнавання мовлення і транскрипції у 2025 році. Для нетехнічних користувачів — MacWhisper або Whisper Web дають потужний інструмент без жодного коду. Для розробників — два рядки Python-коду або простий API-виклик. Для максимальної приватності — локальна установка де аудіо ніколи не покидає комп’ютер. Починайте з Whisper Web у браузері прямо зараз — і переконайтесь у якості транскрипції власноруч.

🎤 Як користуватися Whisper від OpenAI: повний гайд з розпізнавання мовлення і транскрипції
🎤 Open-Source ASR · MIT Ліцензія Whisper — найточніше open-source розпізнавання мовлення Транскрипція аудіо · Переклад мовлення · 99+ мов…

🎶 Як користуватися Udio AI: повний гайд від першого промпту до готового треку
🎶 AI Music Generator · Серйозний конкурент Suno Udio AI — глибока інструментальна музика з AI Текстовий промпт → вокал…

🎵 Як користуватися Suno AI: повний гайд зі створення музики від промпту до готового треку
🎵 AI Music Generator · Лідер ринку Suno AI — повноцінна пісня за 30 секунд Текстовий промпт → вокал +…